
Threat model steps
Every entry in the following data will have an ID that can be referenced in the TM itself or by the tools processing the TM data. It is advisable to use unique identifiers in the breaded scope (company/product/component). For example, an ID would then have a structure similar to PPP.SSS.NNN where PPP is the project or product name, SSS is the section and NNN is the sequential inside the analysis. This is just a basic idea of an identifier that should help also to compose different TM into one by avoiding collision of IDs and to reference the same architectural components.
Scope definition
High-level security requirements/compliance level
This will consist of a list of descriptive requirements. High-level security requirements are those that would exist before designing the software itself and are often business-related. Compliance like PCI-DSS, ISO-XXX, FEDRAMP, are examples of high-level security requirements that are better to capture at the beginning of the TM.
The parts of the Scope section helps also to coordinate the work on a team performing a threat modeling. It is in practice not uncommon that an overzealous contributor may think of many unlikely threats that are easy to claim but difficult to confute. This kind of contribution has often a sentence structure of "What if <insert here a not so in scope/non-plausible event>?". That's why I call it the "What if...?" problem. "What if the earthquake...? What if the quantum computer...? What if the administrator user gets rogue?" Many entries in the Scope section are created during the later Analysis phase. Many considerations of the scope that some people give for granted given their experience and knowledge of customary software architecture are not so obvious to other participants in the analysis and to other threat model consumers. For example, What if the administrator of X system user gets rogue? may create an explicit entry in the Attackers section, as "out of scope" for the analysis (of course this is arbitrary, e in other threat model this may well be in-scope).
Level of abstraction
Threat modeling, as other development practices like testing, can go on indefinitely and infinitely. The resources to implement the threat model are never infinite and we know the findings and the benefit follow a Pareto distribution: most of the benefits are concentrated in the first part of the effort. On the other hand, we still need to define a criterion of completeness. Precisely defining a level of abstraction (all abstraction are a simplification of the real system) is a way to transition from an endless exercise of finding "whatever thing that can go wrong" to a finite exercise where we gain confidence of completeness, that, at a precise level of analysis, we apply a consistent analysis that will not overlook crucial security features or threats. Without this holistic approach, the risk is to apply a lot of effort to some security features while ignoring others, and this is a big failure, like fortifying a defensive wall in a mediaeval castle while leaving a gate or another passage accessible to attackers. While predicting the total effort is not a precise exercise defining a level of abstraction and enumerating the systems, assets, data flows, and cone of trusts will give us a good approximation of the total effort and of the work advancement. The level of abstraction also defines some of the methodologies that best suit the analysis, a data flow diagram that represents the whole of company's data flows will be far more abstract than a single system developed using a set of micro-services. For multi-system analysis, a P.A.S.T.A. approach would be more suitable. For a software platform or service, the level of abstraction to perform the analysis should have a more detailed level, for example, the C4-model convention at a container or system level. The methodology of analysis, in this case, could follow a framework like STRIDE. This by the way is the more common level of abstraction TM is applied to, at least in my experience, and the following examples will follow that single-system level of abstraction. This is usually close to that or one o few development teams concurring in creating a sellable reusable software product. A level of abstraction could be also more fine-grained, then, we talk about Abuse Cases and in-Story Agile Threat Modeling (see https://blog.secpillars.com/2019/06/practical-threat-modeling-series-part-4.html ). Combining different levels of analysis in a consistent framework and with consistent, or at least compatible, data structure and IDs is a key feature to having a maintained and actionable TM that grows incrementally and consistently over time. Threat model should not be a once heroic effort.
Assets and dataflow enumeration (in or out of scope)
Assets and dataflow enumeration (in or out of scope)
Trust zones and their definition
Trust zones are a hierarchy of places in which every zone has the same trust, trust is abstracted here by attributes such as homogeneous attackers reachability, access credentials, sensitivity of information. I do not have here a formal definition of a zone of trust, while designing or reviewing a system the designers need to have an intuitive understanding of what a zone of trust is, this is usually the case and is not problematic.
An Example of an highly trusted zone is the database where customers credit card numbers are stored, called CDE (cardholder data environment” ) in PCI DSS compliance: https://www.pcisecuritystandards.org/pci_security/glossary. This environment will be assigned a high number for example 5 (Trust zone 5). The open internet is usually Trust Zone 0. An internal system that has no direct access to the credit card numbers but accomplishes some less critical business function while being part of an internal network may be assigned Trust Zone 2. Communications (dataflows) inside the same zone of trust may not require authentication or authorization (defence in depth principles like zero trust networks may be expressed as properties of zones of trust). Specific threat categories apply to asset/data stored in a zone of trust. Data flowing from a lower to a higher zone of trust will be subjected to data integrity issues while data flowing from a lower trust zone to and higher trust zone will be vulnerable to information disclosure issues. This trust zone analysis really helps to have an adequate and consistent level of security across the part of the system and it is possible to apply specially developed techniques of threat model analysis based on zone of trust, for example RAPID methodologies developer by Geoffrey Hills: https://github.com/geoffrey-hill-tutamantic/rapid-threat-model-prototyping-docs
In my experience the RAPID methodology of analysis is a perfect complement for S.T.R.I.D.E. like methodologies and frameworks.
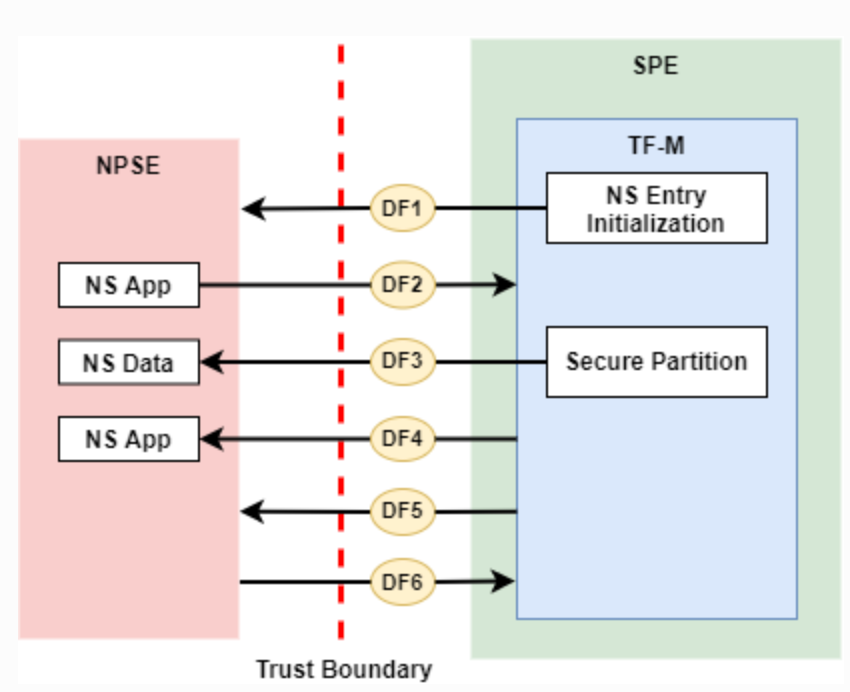
This is an example from 1* of trust zones (lower trust on the left of the boundary, Non-secure Processing Environment: NSPE) and dataflows (DF1 to DF6) crossing that boundary.
Attacker/Threat agents
Is good to identify (generally) the kind of attacker that we expect or not to pose a threat to the system we are modeling for security. Here are some examples:
Sometimes the term "attacker" is not linguistically appropriate. Some system (hardware) needs to be resilient to exposure at low temperatures, or cosmic rays interferences. For this kind of threat the term "threat agent" may be preferred.
Captured assumptions (fed in from the analysis below)
This section is essential to preserve the history of the choices. It will be initially almost empty and be populated during the later analysis phase. It is still logically belonging to the scope section as prerequisites and conditions that were not captured before the analysis. A prerequisite that makes our analysis consistent over time. This assumption should be also used when developing a new feature in a checklist manner.
Analysis (STRIDE, CIA, LINDDUN, brainstorming)
While there are several techniques and frameworks to identify threats and vulnerabilities, for example Attach Trees, kill chains, etc ( https://www.schneier.com/academic/archives/1999/12/attack_trees.html ) the STRIDE taxonomy and framework demonstrated its validity and efficiency over time, and is a well know de-facto standard.
STRIDE is both a framework and a taxonomy of threats. We describe below the use of the framework with a more concise taxonomy: C.I.A. (Confidentiality, Integrity, and availability), the essence of the analysis is not different. Parallelism between S.T.R.I.D.E. and C.I.A. or how to render custom taxonomies given the system in analysis is out of the scope of this writing.
Once we have a scope definition to start with, we can then start thinking of what can go wrong.
Following the high-level thinking suggested by Adam Shostack, the scope definition helps us to answer the first of the 4 questions on TM "What are we building?". The Analysis part will answer the "what can go wrong?" and "what are we doing about it?" questions.
Once again, "What can go wrong?" can be an infinite question to answer to. But now we have a better defined and limited scope to work on. One approach is to go over every asset and data flow and see what can go wrong for that specific asset in scope, by an attack performed by a threat agent. A taxonomy of all possible wrong outcomes can help us also to identify those specific things that can can wrong, effectively helping us to apply an adversarial mindset that is very different from the mindset we apply to software creation at the time of implementing a functional requirement. Useful taxonomies are C.I.A. (Confidentiality, Integrity, and availability). The analysis exercise will iterate over the asset and dataflows in scope, over the taxonomy, over the attackers. Here is a logical representation, the bare minimum that needs to go be thought by the analyst:
FOR each ASSET in scope
FOR each ATTACKER in scope
FOR each THREAT CATEGORY in C.I.A.
Answer: What can go wrong for the ASSET given an attack by ATTACKER for the aspect of THREAT CATEGORY ?
END FOR
END FOR
Answer: Is there something else that can go wrong that was not included so far ?
END FOR
The above algorithm produces a finite number of though exercises. It is not automatic or granted at this point to identify the vulnerability and their mitigations in place or not. Some degree of Software security expertise is essential to answer that central question. What his framework gives is an approach that results in a "best effort" given the limited resources and given a Pareto Distribution of things that likely go wrong. The main goal is to collect low and medium hanging fruits. This is especially true is compared with other frameworks for threat modeling: attack trees, reverse attack trees etc TODO
Nesting three iteration, the number of ASSET/DATAFLOWS, ATTACKERS and the 6 STRIDE threat groups can still sum up to a big number. If we identify 10 assets/dataflows, 3 attackers in scope , we'll have 10 x 3 x 3 = 90 questions to go through.
Given:
DATAFLOW = Edit API endpoint
ATTACKER = Editor User
THREAT CATEGORY= Availability (lack of)
One analysis question will look like: "What can go wrong with a logged in Editor user attacking to create a lack of Availability on the Edit API enpoint?"
This question may have 2 answers (flaws/vulnerability):
1) The user sends a high number of request in a short period of time (flooding)
2) The user send a log data string (50MB or more) generating a logged error that exhaust the log capacity of the server disk.
We may have or not mitigations for the above vulnerability. In any case the threat model should document it. The threat model in this case will be useful to both highlights the unmitigated vulnerabilities as well as document the mitigations, controls and countermeasures in place.
To perform and track analysis completion my advice is not to use too many tables. A simple 2 dimensional table with nested annotations may contain the essence of the analysis even if the 3 nested iteration above may suggest otherwise. In this example the analysis shows in one row the analysis for a DataFlow (edit endpoint). If we have threat on C.I.A there will be a numerated entry that shortly describes it nature status. More detailed information should be delegated to a proper tracking tool (Jira tickets or similar); in the following example there is a tracking ticket for the only identified unmitigated vulnerability 'VULN_001'. Mitigated vulnerabilities like those identified for Confidentiality or Integrity in the example may not have a tracking ticket. The threat model and its extraction are documenting itself the security features.
Other attributes could be annotated in the Analysis table, for example the severity scoring, in this case: CVSS 6.1 (MEDIUM) https://www.first.org/cvss/calculator/3.1#CVSS:3.1/AV:N/AC:L/PR:L/UI:N/S:U/C:N/I:N/A:H
The analysis table and the taxonomies are mere tools. The analysis should not be limited by them. If by experience, suggestion, incident occurred, brainstorming, etc. a vulnerability is identified and it does not fit the analysis table or technique, a special entry needs to created, in this case consider adding a column "Other".
Flaws and their mitigations results (with all the necessary attributes: in place yes/no...)
An auxiliary table for identified vulnerabilities, containing more data fields about them cab be detailed. Especially if this if not integrated with a tracking system.
Threat model Data extractions
Given the Scope defined and the analysis performed there are useful data structure available to create different reports that can have different use cases.
Full report
This extraction will be very similar to the threat model created so far. It can still differ in the medium , the annotations the format etc. On bigger systems and TM can be divided into components (some asset/dataflows in scope for a TM). It would be also possible to compose a TM based on the composition of reusable ones. If this asset (diagrams) are coherent, it is possible to compose a bigger TM starting from a multiplicity. This should be planned in advance.
Unmitigated Vulnerabilities
This extraction are the jewels of the threat model. Very useful to improve and have a knowledge of the security posture of a system as well a confidential.
Non-confidential/distributable version of the TM
When a counterparty (a customer) ask what are you doing about the security of the product, having a distributable , probably under a NDA, version of a non too confidential (should not expose unmitigated vulnerabilities) is a competitive advantage. This same extraction could be used for open source, compliance etc.
Here is an example of a published result form the example 1*:

This other example is from 2*

Even with a different terminology, in the most generic terms, both examples show something that can go wrong and what to do about it.
Metrics
It is possible also to track and extract metrics of the TM and applied efforts and completeness of analysis.
This will contribute to optimisations, compliance and to better evaluate the resources necessary in the process.
Comments
Post a Comment